2020. 1. 21. 14:34ㆍSecurity/oracle database
* 사용자 데이터 저장(테이블의 물리적인 형태)

일반 테이블(regular table)
- 테이블의 크기가 크다.
- 데이터베이스 내에 데이터를 저장하는 가장 일반적인 수단
- 테이블 세그먼트는 클러스터화되거나 분할되지 않은 테이블에 대한 데이터를 저장.
분할 테이블(partitioned table)
- 사용자는 테이블이 분할된 것을 모르기때문에 일반 테이블과 똑같이 사용
- 테이블을 어떻게 사용할지 명확히 판단하고 분할
- 데이터베이스 관리의 용이성이 크다.
인덱스 구성 테이블(index-organized table)
- 테이블 안의 행을 정렬해서 저장. 순서가 있는 것은 아니다.
- 기본 원칙을 위배했기 때문에 현재는 없어졌다.
클러스터(cluster)
- 물리적으로 다른 영역에 있지만 항상 같이 읽히는 데이터들을 같이 저장하기 위해 사용
- 옵티마이저(명령의 실행장치)가 무조건 클러스터를 사용하려고 하기때문에 유의
- 전체적인 프로그램의 계획들을 보고 그에 알맞춰서 구성
* 오라클 내장 데이터 유형

char(n)
- 정해진 n의 길이 만큼 무조건 공간 차지. char 대신 varchar를 사용한다.
varchar2(n)
- n의 길이만큼 입력을 할 수 있지만 무조건 공간을 차지하지 않는다.
nchar(n)
- national char. 영어 이외의 다른 언어로 되어 있는 문자를 데이터로 저장할 수 있도록 함.
number
- 숫자 타입
date
- 날짜 타입.
- 시리얼 번호로 되어있기때문에 우리가 알아볼수 있게 출력해야 함.
raw
- 이진 데이터 저장 가능.
- 지금 나(관리자)의 입장에서는 사용하지 않는다.
blob, clob
- lob는 large object를 의미.
- 테이블 외부 object에 저장.
- pl/sql 프로그램에서 사용.
rowid
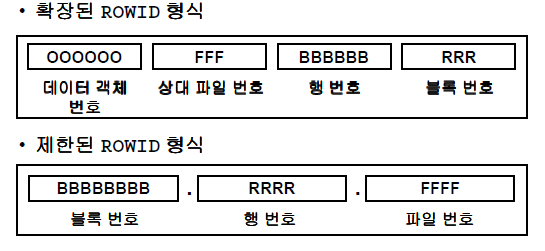
- 행의 물리적인 위치 정보.
- 예전에는 제한된 ROWID 형식(Restricted ROWID Format)을 사용. 크기가 쓸데없이 크기 때문에 현재는 사용하지 않음.
- 확장된 ROWID 형식(Extended ROWID Format) 세그먼트의 고유 정보를 통해서 관리
- rowid는 index에 저장되어 있다.
* row(행)의 구조

- 블록단위로 읽어오기때문에 행의 구조는 상관없다.
- 데이터베이스 블록이 읽힐때 row도 같이 읽힌다.
* 테이블 생성

CREATE TABLE hr.employees( // 다른 스키마에 테이블을 생성 하는 것을 알 수 있음.
employee_id NUMBER(6),
first_name VARCHAR2(20),
last_name VARCHAR2(25), // 성과 이름 따로 저장
email VARCHAR2(25),
phone_number VARCHAR2(20),
hire_date DATE DEFAULT SYSDATE,
job_id VARCHAR2(10), // job이라는 테이블의 릴레이션 코드로 추정
salary NUMBER(8,2),
commission_pct NUMBER (2,2), // 급여의 퍼센티지. 릴레이션 코드로 추정
manager_id NUMBER(6),
department_id NUMBER(4) // 부서의 id. 릴레이션 코드로
);
테이블 생성 가이드 라인
- 테이블을 되도록 테이블 스페이스에 분산해서 위치.
- 단편화를 방지하려면 지역적으로 관리되는 테이블 스페이스를 사용(locally management 테이블스페이스를 쓰면 해결)
- 테이블 스페이스 단편화를 줄이려면 가급적 테이블의 표준 확장 영역 크기를 사용을 피해야 한다.(locally management 테이블스페이스를 쓰면 해결)
*ROW migration and chaining(행 이전 및 체인화)

- 오라클은 row chaining을 허용하지 않지만 블록 사이즈보다 행이 훨씬 클 경우 발생.
- migration이란 기존의 행을 늘릴때 빈공간이 없을때 행을 다른 곳으로 이동. rowid값과 rowid값이 저장되어있는 index도 수정해야 한다.
- migration을 방지하기 위해 빈 공간(PCTREE)을 최대한 많게 지정해야 하는데 사용자가 지정할 수 없음.
Manually Allocationg Extents(확장 영역 수동 할당)

- 공간 할당하는 업무가 시스템에 부담이 되지 않는다.
- 데이터 파일은 저장된 테이블에 관련된 파일이어야 함.
분할되지 않은 테이블 재구성

- 테이블 스페이스 옮기는 것이라고 되어있지만 같은 테이블 스페이스내에 테이블을 지웠다 만들때 사용
테이블 자르기

- 테이블의 모든 행이 삭제되고 사용된 공간도 해제. 즉, 테이블을 새로 만든 것과 같다.
테이블 정보 얻기
- DBA_TABLES 와 DBA_OBJECT를 질의해서 테이블에 대한 정보를 얻을 수 있음.
[실습]Table과 index의 물리적인 관리
- 실습전에 테이블을 만들어 주는 school_table.sql, 데이터를 입력해주는 school_data.sql, 제약조건을 설정해주는 school_constraint.sql을 반드시 먼저 만들어준다.
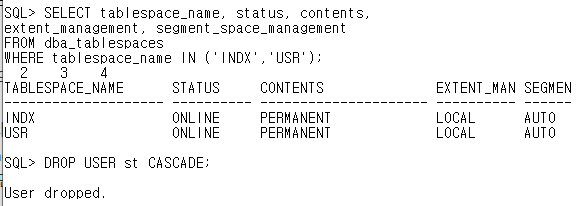
CREATE TABLESPACE usr
DATAFILE '/app/ora12c/oradata/disk1/usr01.dbf' SIZE 20M,
'/app/ora12c/oradata/disk2/usr02.dbf' SIZE 20M;
// 예제용 table을 저장하기 위한 tablespace
CREATE TABLESPACE indx
DATAFILE '/app/ora12c/oradata/disk2/indx01.dbf' SIZE 5M,
'/app/ora12c/oradata/disk1/indx02.dbf' SIZE 5M;
// index를 저장하기 위한 tablespace


CREATE USER st
IDENTIFIED BY st
DEFAULT TABLESPACE usr
QUOTA UNLIMITED ON usr;
// 예제용 스키마 생성
GRANT connect, resource TO st;
// 권한 부여
CONN st/st
// Table이나 Index 생성 작업은 반드시 st로 접속한 다음 수행.
@school_create_table
@school_insert_date
@school_constraint
// Table은 usr tablespace에 Index 는 indx tablespace에 생성하도록 스크립트를 작성한다.
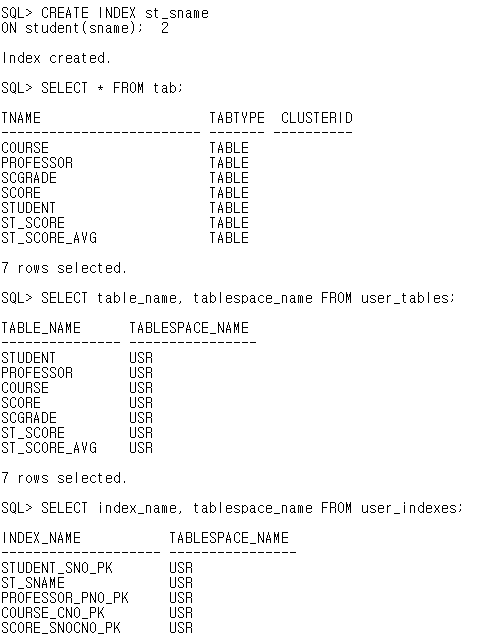
CREATE INDEX st_sname
ON student(sname);
// 인덱스를 정렬해서 순서대로 저장
SELECT * FROM tab;
SELECT table_name, tablespace_name FROM user_tables;
// st로 로그인 되어있기때문에 dba_tables를 조회할 수 없음.
SELECT index_name, tablespace_name FROM user_indexes;
// 인덱스, 테이블 스페이스 조회. PK와 UK를 지정해서 인덱스가 생성되어 있는 것을 확인.

SELECT count(*) FROM student;
SELECT count(*) FROM professor;
SELECT count(*) FROM course;
SELECT count(*) FROM score;
'Security > oracle database' 카테고리의 다른 글
| 오라클 데이터베이스 관리자 기초- (14)데이터 무결성 유지 관리 (0) | 2020.01.23 |
|---|---|
| 오라클 데이터베이스 관리자 기초- (13)인덱스 관리 (0) | 2020.01.22 |
| 오라클 데이터베이스 관리자 기초- (11)암호 보안 및 자원 관리 (0) | 2020.01.16 |
| 오라클 데이터베이스 관리자 기초- (10)권한 관리 및 롤 관리 (0) | 2020.01.14 |
| 오라클 데이터베이스 관리자 기초- (9)사용자 관리 (0) | 2020.01.14 |